FiFoSiM – An integrated tax benefit microsimulation and CGE model for Germany
- ISER and University of Cologne, Germany
- University of Cologne, Germany
Abstract
This paper describes FiFoSiM, the integrated tax benefit microsimulation and computable general equilibrium (CGE) model of the Center of Public Economics at the University of Cologne. FiFoSiM consists of three main parts. The first part is a static tax benefit microsimulation module. The second part adds a behavioural component to the model: an econometrically estimated labour supply model. The third module is a CGE model which allows the user of FiFoSiM to assess the global economic effects of policy measures. Two specific features distinguish FiFoSiM from other tax benefit models: First, the simultaneous use of two databases for the tax benefit module and second, the linkage of the tax benefit model to a CGE model.
1. Introduction
The aim of this paper is to describe FiFoSiM, the integrated tax benefit microsimulation and computable general equilibrium (CGE) model of the Center for Public Economics (CPE) at the University of Cologne (Finanzwissenschaftliches Forschungsinstitut an der Universität zu Köln (FiFo)). Fuller documentation is provided by a number of unpublished working papers including Peichl and Schaefer (2006), which is a shortened English version of a more detailed German description (Fuest et al., 2005b), all available from the project website (www.cpe-colgone.de). FiFoSiM consists of three main parts. The first part is a static tax benefit microsimulation module. The second part adds a behavioural component to the model: an econometrically estimated labour supply model. The third module is a CGE model which allows the user of FiFoSiM to assess the global economic effects of policy measures. Two specific innovations distinguish FiFoSiM from other tax benefit microsimulation models for which peer-reviewed accounts are available: first, the simultaneous use of two databases for the tax benefit module and second, the linkage of the tax benefit model with a CGE model. The paper is notable also for bringing into one place discussions of a range of ‘standard’ techniques, including statistical matching, imputation, and implementation of both CGE and discrete choice household labour supply models. Hence, in addition to presenting the methodological innovations already alluded to, it is hoped that this paper will serve as a jumping-off point for others involved in planning, constructing and refining similar models.
The basic module of FiFoSiM is a static microsimulation model for the German tax and benefit system using income tax and household survey micro data. In the last few years a number of tax-benefit microsimulation models have been developed for Germany. (For example, Peichl, 2005; Wagenhals, 2004.) Most of these models use either GSOEP or FAST as a database. FAST is a micro datafile from the German federal income tax statistics containing the relevant income tax data of nearly 3 million households in Germany. GSOEP, the German Socio-Economic Panel, is a representative panel study of private households in Germany. The approach of FiFoSiM is innovative in that it creates a dual database drawing upon both micro datasets. The simultaneous use of both databases allows for the imputation of missing values or variables in either dataset using techniques of statistical matching.
Figure 1 shows the basic setup of FiFoSiM. The tax benefit module follows several steps. First, the database is updated to the ‘current’ year using static ageing techniques. Cases are reweighted to allow for projected changes in global structural variables, whilst a differentiated adjustment is implemented for different income components of the households. (Gupta and Kapur (2000) provide a more detailed overview of static ageing techniques.) Second, we simulate the current tax system using the modified data. The result of this simulation provides the benchmark for different reform scenarios, which are also modelled using the updated database.
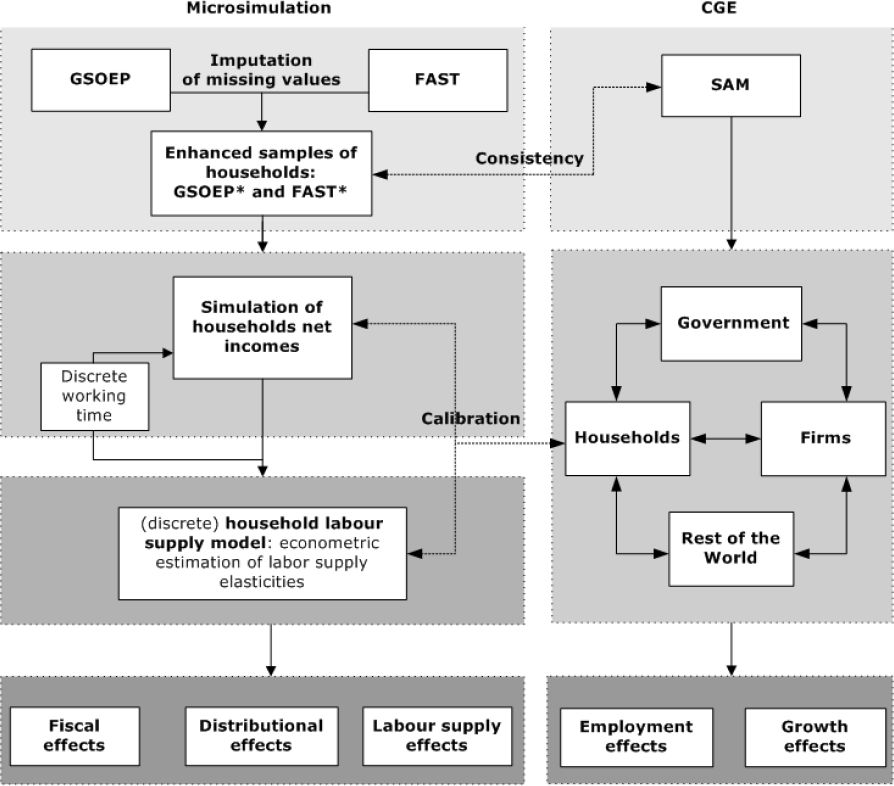{kind=link}
Basic setup of FiFoSiM.
In order to model the tax and transfer system, FiFoSiM computes individual tax payments for each case in the sample considering gross incomes and deductions in detail. The individual results are multiplied by the individual sample weights to extrapolate the fiscal effects of the reform with respect to the whole population. After simulating the tax payments and the received benefits we can compute the disposable income for each household. Based on these household net incomes we estimate the distributional and the labour supply effects of the analysed tax reforms. For the econometric estimation of labour supply elasticities, we apply a discrete choice household labour supply model. Furthermore, FiFoSiM contains a CGE module for the estimation of growth and employment effects, which is linked to the tax benefit module. This interaction allows for a better calibration of the model parameters and a more accurate estimation of the various effects of reform proposals.
The organisation of this paper is as follows. Section 2 describes (the creation of) the dual database of FiFoSiM, while Section 3 describes the tax benefit module. Section 4 contains a description of the labour supply model, while Section 5 describes the CGE module. In Section 6, several applications of FiFoSiM are presented and some developments planned for the further improvement of FiFoSiM are outlined.
2. Database
A specific feature of FiFoSiM is the simultaneous use of two micro databases, allowing for the imputation of missing values or variables in both datasets. Due to the time lags between data collection and data availability, the two datasets have to be updated to represent the German economy in the period of analysis. The two data sources, and the matching and ageing processes applied to them, are described in detail in the following. The use of a third database in the CGE module is described separately (Section 5).
2.1 Income tax scientific-use-file (FAST)
Federal income tax statistics are published every three years, with a time lag of five to six years. These statistics contain all of the information from the personal income tax form (e.g. source and amounts of incomes, deductions, age, children), for every household subject to income taxation in Germany. For 1998, almost 30 million households were included in the micro database. FAST98 is the scientific-use version of this database, containing a 10% sample of the German federal income tax statistics, including the relevant tax data of nearly 3 million households. The results presented in this paper are based upon use of FAST98. Subsequently, FiFoSiM has been updated to use the 2001 FAST release.
The FAST microdata are especially suitable for a detailed analysis of the German tax system. All structural characteristics of the taxpayers are well represented, allowing for a differential analysis of tax reforms. Merz et al. (2005) provide full details. However, FAST does not contain information on working hours and hourly wages.
2.2 German socio-economic panel (GSOEP)
The German Socio-Economic Panel (GSOEP) is a representative panel study of private households in Germany that has been running since 1984. In 2003, GSOEP consisted of more than 12,000 households comprising more than 30,000 individuals. The data includes information on earnings, employment, occupational and family biographies, health, personal satisfaction, household composition and living situation. The panel structure of GSOEP allows for longitudinal and cross-sectional analysis of economic and social changes. GSOEP contains information about the working time and the social environment of the households which is used by FiFoSiM for the labour supply estimations. For further details on GSOEP see SOEP Group (2001) and Halisken et al., (2003).
Bork (2000) has confirmed that GSOEP provides a representative cross-section of labour incomes, but notes that capital and business income are less well represented. Of particular note, the bottom end of the income distribution is better represented in GSOEP than in FAST.
2.3 Creating the dual database
One special feature of FiFoSiM is the creation and usage of a dual database. To be more precise, FiFoSiM actually consists of two tax benefit microsimulation models. The first one is based on administrative tax data (FAST), the second on household survey data (GSOEP). The main reason for using a dual database instead of having only one merged database is the huge difference in the number of observations (3 million vs. 30,000). Furthermore, both databases have shortcomings, as described in the previous sections. Technically, cases in the two datasets could be matched with each other through the use of unique personal identifiers. In Germany, however, there are legal barriers to such a solution. Instead, FiFoSiM relies upon statistical matching. In this way information from one database is used to impute missing values or variables in the second dataset and vice versa. The end result is that FiFoSiM actually consists of two enhanced datasets, which allows for a better analysis of tax benefit reforms than using either original dataset alone.
There exist several principal ways for statistically matching datasets and imputing missing values. Rässler (2002) gives an introduction to statistical matching procedures and imputation techniques, as well as an overview of the vast literature and software packages that exist. D’Orazio et al. (2006) provide an alternative introduction to well-known techniques originally developed during the 1970s (c.f. Okner, 1972; Radner et al. 1980), whilst more recent developments in imputation methods are outlined by Rubin (1987) and Little and Rubin (1987). Finally, Cohen (1991) provides a survey of statistical matching applied in other fields of research. However, although statistical matching and missing value imputation are well established approaches, as far as we know no peer-reviewed microsimulation model has previously adopted the dual database solution of FiFoSiM. The remainder of this Section (2.3) reports the methods of imputation and statistical matching used by FiFoSiM. The problem of database updating is then considered in Section 2.4, before the strengths and limitations of this dual database approach are returned to in Section 2.5.
2.3.1 Imputation of missing values
When faced with missing values in one variable the best, but of course most expensive, way to impute the missing values would be to collect further information on the missing data. But even this solution cannot compensate for shortcomings in historic datasets. An alternative would be to delete (or at least omit) cases containing missing values. However, this procedure would lead to biased estimations if the people with missing values share the same characteristics. Instead, as we review below, a number of statistical approaches offer better solutions.
In general, the imputation of missing values stands for replacing missing data with “plausible values” Schafer (1997: 1). Let K be a variable from a dataset A with i non-missing values N = (n1,n2,...,ni) and j missing values M = (m1,m2,...,mj): K = (N,M) = (n1,n2,...,ni, m1,m2,...,mj), and O = (O1,O2,...) a vector of (other) variables without missing values. At the same time, but for a different dataset, B, let H be the same variable as K and P the same as O. A range of solutions to finding ‘plausible’ values of M exist.
Mean substitution
In this approach, the missing values M in variable K are either substituted by the mean of the non missing values N:
or they are substituted by the mean of the same variable H from a different dataset B:
If the missing values can be attributed to some specific subgroups, then the missing values for each subgroup are replaced by the mean of each subgroup from the non missing values of either K or H.
Mean substitution reduces the variance of K and should therefore be an option of last resort, only considered if other approaches outlined below are not applicable. The latter could be the case if, for example, there is no correlation between K and any other variable. Mean substitution is used in FiFoSiM if a reform proposal includes the taxation of a so far untaxed activity, the distribution of which is not captured in an existing micro dataset.
Regression
In the regression approach, a function for the estimation of the missing values is constructed by regressing N, the non-missing values of K on other (non missing) variables O:
Or, as in the case of mean substitution, the similar variable of non-missing values of H from a different dataset B are regressed upon P, the other variable present in B.
These regression coefficients β are then used to predict the missing values. Often a stochastic random value û is added to the prediction of the missing values M to allow for more variation:
or
These estimates are then used to replace the missing values M:
In FiFoSiM this approach is mainly used for variables originating in the FAST98 database. Most of the missing values in FAST are due to anonymisation; their plausible values can be restricted to specific intervals given the additional information captured by the other non-missing variables. For categorical variables logistic regressions are often undertaken. Greene (2003) provides a good introduction to the different regression techniques available.
Multiple imputation
In the multiple imputation approach, multiple values for each missing value are simulated. That is, the missing data is filled in q times using the regression approach, each time, with different draws from the distribution of the stochastic error term to generate q complete data sets. These multiple datasets are generated to better reflect the variation in the estimates and the uncertainty in the imputation procedure itself:
Hence it is possible to compute the variance, and confidence interval or P-value of the missing value.
The average of these estimate values,
provides the estimator for the relevant missing values and is used to replace the missing values, M, in the original dataset.
This approach is used in FiFoSiM for most of the GSOEP variables containing missing values. The relatively small number of cases in the GSOEP allows the use of several simulation runs for the imputation in a few minutes, whereas for the FAST data this method takes noticeably longer.
2.3.2 Statistical matching
Ideally, one would like to find perfect matches all of the time. This is possible if one has access to variables which uniquely identify an individual, such as name, address, date of birth, social security number. In reality, for reasons of respondent confidentiality, researchers are not allowed to gain access to raw micro data that includes this information. Instead, access is provided to anonymised datasets in which uniquely identifying characteristics have been removed or modified. As a result, exact matching is not possible. We therefore have to use methods of statistical matching to match close (instead of exact) observations that share a set of common characteristics.
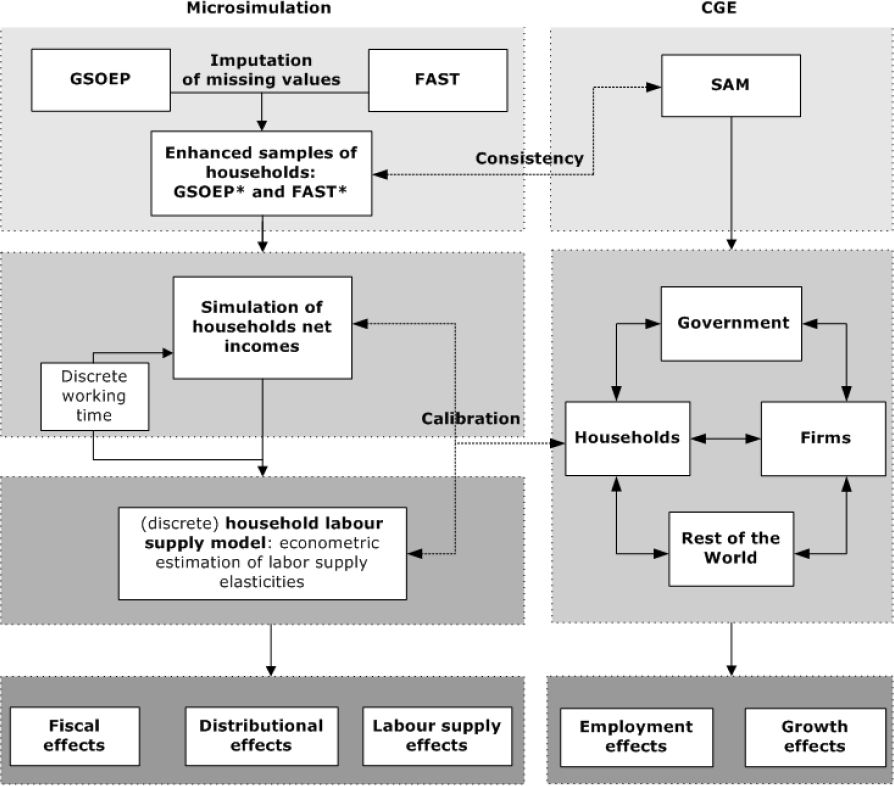
The idea of combining two existing datasets to create a joint dataset was developed during the 1970s (c.f. Okner, 1972; Radner, 1980; Cohen, 1991). The general principle is to merge two (or more) separate databases through the matching of the individual cases. This matching is performed on common variables that exist in both databases (for example gender, age and income). The idea underlying this statistical matching approach is that if two people have a lot of things in common (like for example age, sex, income, marital status, number of children), then they are likely to have other characteristics (like for example expenses) in common.
Figure 2 illustrates this basic idea of statistical matching. To put it more analytically, following Sutherland et al. (2002), we have three sets of variables X,Y,Z and two samples A = (X,Y) and B = (X,Z). X are the common variables in both samples (for example gender, age and income), Y and Z are sample specific (for example hourly wages and working hours from GSOEP, special tax deductions from FAST). We can now create a new, joint sample C = (X,Y,Z) by merging a recipient sample (let’s say A) with observations from a donor sample (b) with exact (or close) values of X. In doing so, one assumes that the conditional Independence Assumption (CIA) holds: conditional on X, Y and Z are independent. In other words, if we know X, Y(Z) contains no additional information about Z(Y) (Sims, 1972a, b, 1974). This assumption can “in practice […] rarely be checked” (Sutherland, Taylor and Gomulka (2002: 519). However, if the CIA does not hold, Paass (1986) observes that one can still use methods of statistical matching if the relationship between Y and Z can be estimated from other sources and incorporated into the matching process.
{kind=link}

The basic principle of statistical matching.
As outlined below, statistical matching of two databases can be tackled using regression or data fusion methods. Note that which sample is chosen as the recipient, and which as the donor, depends upon the particular matching problem.
Regression
In the regression approach, the specific variable from the donor dataset Z is regressed on the vector of common variables X:
Often a stochastic random value V is added to the prediction to allow for more variation:
The estimated coefficients β from the donor dataset are then used to predict the values of Z in the joint dataset:
A strong correlation between X and Z is important for a successful merging. This approach is rather easy to perform, but it has the drawback that information in terms of variation is lost in the second dataset.
Data fusion
There are two main approaches to data fusion: nearest neighbour and propensity score matching. The general idea of both approaches is the same; they differ in detail only in the first step.
The first step in the nearest neighbour approach is to weight and norm the common variables, whereas in the propensity score approach, the first step is to estimate a propensity score, defined as the conditional probability of treatment given (the common) background variables (Rosenbaum and Rubin, 1983). In other words, the propensity score is used as a predictor of the probability of being in the treatment group versus being in the control group. In our case, an observation is in the treatment (control) group if it comes from the recipient (donor) sample.
To estimate the propensity score, a dummy variable I is introduced into the pooled dataset D, containing the common variables X from both samples A and B, with a value of 1 if the observation is from the recipient dataset and 0 if it is from the donor dataset:
Then a logit or probit estimation of the probability of the observation being from the recipient sample (that is of the dummy indicator variable being 1), conditional on the common variables X, is calculated:
The function f(Xβ) is called the propensity score and indicates the probability of the observation belonging to the treatment group (the recipient sample).
The second step is similar for both approaches. The distance between the observations from both datasets is computed using a distance function (for a discussion of which, see Cohen, 1991). In the nearest neighbour case, the distance is based on the weighted common variables. In the propensity score case, the distance is based on the estimates for the propensity scores, which can be interpreted as some sort of implicit weighting function.
In the third step, the joint database C = (X,Y,Z) is created by merging the observations from the two datasets A and B with the minimal distance between them. Three ways of merging are possible: one observation from the donor dataset is merged to one observation from the recipient dataset (one-to-one merging); or one observation from the donor dataset is merged to multiple observations from the recipient dataset (one-to-n merging); or multiple observations from the donor dataset are merged to multiple observation from the recipient dataset (n-to-m merging).
In FiFoSiM the type of statistical matching used is determined by the number of observations (3 million vs. 30,000). In general, information from the smaller GSOEP dataset is matched to the FAST data using the regression approach. FAST information is merged to GSOEP data using propensity score matching.
2.4 Updating the data samples
The database is updated to the year of analysis (i.e. 2007) using static ageing techniques which allow changes in global structural variables to be accounted for, whilst allowing differentiated adjustment for the different household income components. Most importantly, the income tax data sample needs to be updated as it describes the situation of 1998. The GSOEP data only needs to be adjusted from 2002. The use of different ageing factors for each database and reweighting to the same control totals helps to ensure consistency between the two databases.
Gupta and Kapur (2000) provide an overview of techniques to update data for the use in microsimulation models. In FiFoSiM the first step is to reproduce the fundamental structural changes of the population. This is done according to the following criteria: age (in 5 year categories), assessment for income tax (separate or joint) and region (East/West Germany). The method applied here follows Quinke (2001). The cases from the FAST sample are compared to aggregated statistical data for the whole population using the above named criteria to calculate the degree of coverage. Assuming that this degree remains stable over the years, the actual aggregate population statistics and prognosis for the year 2006 multiplied by the coverage degree allows for an approximate adjustment of the database to account for the basic structural changes. Technically, the sample weights need to be adjusted. The weighting coefficients indicate how many actual cases of the real population are represented by each case in the sample. Using the software package Adjust (Merz et al., 2001), the sample weights are adjusted according to 52 possible combinations of the attributes (13 age categories times 2 assessment types times 2 regions). As a result of using the adjusted weights the updated sample represents the current population structure better.
In the second step, the taxpayer’s incomes are updated with respect to the varying development of different income types. As well as positive and negative incomes, differences in income growth rates between West and East are taken into account. This allows for a differentiated estimation of income development. Based on empirical research reported in Bach and Schulz (2003), different coefficients for positive and negative incomes are applied to each case’s income. For the simulation model this means that each income value is multiplied with the relevant coefficient and thus extrapolated to the current income level. Of course, the coefficients only represent average development, but regarding the whole population this method provides a satisfying approximation of the current income structure.
2.5 Strength and limitations of the dual database
The use of the dual database and the two tax benefit microsimulation models based on the two enhanced datasets (FAST* and GSOEP*) allows us to both check consistency between the two models and to choose the model which is most appropriate for each particular problem we want to analyse. However, these methods cannot guarantee the resulting datasets will retain all of the advantages of both databases. Beside the huge difference in size, using methods of statistical matching leads to the loss of case-specific information. Nevertheless, both datasets are each enhanced through external information while maintaining their specific advantages. If, alternatively, the datasets were merged to one single database, a lot of detail and the huge number of cases in FAST would be lost.
Table 1 compares the revenue of the status quo personal income tax system for the years 2005–7, as estimated by the Federal Government, with estimates derived from the original and enhanced FAST and GSOEP datasets. These comparisons show that the original GSOEP values would overestimate the personal income tax in each year, mainly because of missing information about deductions. On the other hand, the original FAST values underestimate the total tax revenue, mainly because of missing information about pension payments which have been taxed more heavily since 1998. These shortcomings are overcome using the enhanced datasets FAST* and GSOEP*. The creation of this dual enhanced database, containing information from both administrative tax data and a household survey, provides the users of FiFoSiM with a powerful tool for the analysis of various questions regarding the German tax benefit system.
Strength and limitations of the dual database.
3. Tax benefit module
In this section, the modelling of the German tax benefit system is described. As the Germany tax benefit system is very complex, we focus on the major parts of the model in this description. A more detailed description can be found in the German version of this documentation (Fuest et al., 2005b).
3.1 Modelling the German income tax law
The basic steps for the calculation of personal income tax under German tax law are set out in Table 2. The reference period used in FiFoSiM for this calculation can be weeks, months or years. The default period is years. The first step is to determine a taxpayer’s income from different sources and to allocate each source to the relevant income type (Section 3.1.1). The second step is to sum up these incomes to obtain the adjusted gross income. Third, deductions like contributions to pension plans or charitable donations are taken into account, which gives taxable income as a result (Section 3.1.2). Finally, the income tax payable is calculated by applying the tax rate schedule to the total taxable income (Section 3.1.3). Individuals are subject to personal income tax. Residents are taxed on their global income. Non-residents are taxed on income earned in Germany only.
Calculation of personal income tax.
| Sum of net incomes from 7 categories (receipts from each source minus expenses) | |
| = | adjusted gross income |
| − | deductions (social security and insurance contributions, personal expenses) |
| = | taxable income (x) |
| . | tax formula |
| = | tax payment (T) |
3.1.1 Income sources
German tax law distinguishes between seven different sources of income: agriculture and forestry, business income, self employment, salaries and wages from employment, investment, rental and other (including, for example, annuities and certain capital gains).
3.1.2 Taxable income
For each type of income, the tax law allows for certain income-related deductions. In principle, all expenses that are necessary to obtain, maintain or preserve the income from a source are deductible from the receipts of that source. The subtraction of special expenses (Sonderausgaben), expenses for extraordinary burden (außergewöhnliche Belastungen), loss deductions and child allowance from adjusted gross income gives taxable income.
Special expenses consist of:
alimony payments (maximum of €13,805 per year)
church tax
tax consultant fees
expenses for professional training (up to €4,000 per year)
school fees of children (up to 30%)
charitable donations (up to 5% of the adjusted gross income)
donations to political parties (up to €1,650)
expenses for financial provision, i.e. insurance premiums (pension schemes up to €20,000 per person; health, nursing care and unemployment insurance)
Insurance contributions are normally split equally between employer and employee. Each premium is calculated as the contribution rate times the income that is subject to contributions, up to the relevant contribution ceiling. Current (2007) contribution rates are 19.9% for old age insurance (€5,200 ceiling in West Germany / €4,400 in East Germany), (an assumed average of) 14.2% for health insurance (€3,525 ceiling), 4.5% for unemployment insurance (€5,200/€4,400 ceiling) and 1.7% for nursing care insurance (ceiling as per health insurance). There are also a variety of special supplements too detailed to enumerate here.
Expenses for extraordinary burden consist of:
expenses for the education of dependants, cure of illness, home help with elderly or disabled people, certain disability-related commuting
allowances for disabled persons, surviving dependants and persons in need of care
child care costs
tax allowances for self-used proprietary, premises and historical buildings
Negative income of up to €5,11,500 income from the preceding assessment period [carry-forward loss] is deductible from the tax base.
Each tax unit with children receives either a child allowance (€2,904 per parent deduction from taxable income) or a child benefit (€154 per month for the 1st to 3rd child, €179 for each additional child) depending on which is more favourable. In practice, each entitled tax unit receives the child benefit. If the child allowance is more favourable, it is deducted from the taxable income, with the sum of received child benefits being added to the tax due. FiFoSiM includes this regulation as it compares allowances and benefits for each case.
Taxable income is computed by subtracting these various allowances and deductions from the adjusted gross income.
3.1.3 Tax due
The tax liability T is calculated on the basis of a mathematical formula which, as of the year 2007, is structured as set out in Equation 15. For married taxpayers filing jointly, the tax is twice the amount of applying the formula to half of the married couple’s joint taxable allowance.
Tax liability calculation formula, 2007
where x is the taxable income.
3.2 Modelling the benefit system
To simulate labour supply effects, the calculation of net incomes has to take the transfer system into account as well. Federal transfers such as unemployment benefit, housing benefit, and social benefits are all modelled in FiFoSiM.
3.2.1 Unemployment benefit I
Persons who were employed and made social insurance contributions for at least 12 months before becoming unemployed are entitled to receive ‘unemployment benefit I’, under the German Social Security Code (SGB III). The amount of benefit paid depends on the average gross income over the preceding period (normally one year). This gross income is reduced by 21% for social contributions and the individual income tax resulting in the adjusted net income. The unemployment benefit I amounts to 60% of the resulting net income (or 67% for unemployed with children). The benefit period depends on age and seniority (Table 3).
Duration of unemployment benefit entitlement.
| Old regulation until 31.01.2006 | New regulation from 01.02.2006 | ||||
|---|---|---|---|---|---|
| Employment period (months) | Age (Years) | Benefit period (months) | Employment period (months) | Age (Years) | Benefit period (months) |
| 12 | 6 | 12 | 6 | ||
| 16 | 8 | 16 | 8 | ||
| 20 | 10 | 20 | 10 | ||
| 24 | 12 | 24 | 12 | ||
| 30 | 45 | 14 | 30 | 55 | 15 |
| 36 | 45 | 18 | 36 | 55 | 18 |
| 44 | 47 | 22 | |||
| 52 | 52 | 26 | |||
| 64 | 57 | 32 | |||
When modelling a person’s labour supply decision their eligibility for unemployment benefits has to be considered. The GSOEP panel data contain information about previous unemployment benefit payments, employment periods and so on, making it possible to model their benefit entitlements.
3.2.2 Unemployment benefit II
All employable persons between 15 and 65 years and the persons living with them in the same household become entitled to unemployment benefit II as soon as they lose entitlement to unemployment benefit I. In contrast to the latter, unemployment benefit II depends on the neediness of the recipient and is therefore meanstested against the household’s net income. Theoretically, need is defined by a household income inadequate to satisfy the elementary needs of all persons living in the household. In practise it is defined by a by a per capita amount set by the State. Unemployment benefit II replaced the former system of unemployment and social benefits, including support for housing and heating costs, in the so-called Hartz reform of 2005.
3.2.3 Social benefits
Since unemployment benefit II was introduced, only persons who are unable to take care of their subsistence are entitled to receive social benefits. These include the non-employable and those facing extraordinary circumstances such as a major health impairment. Analogously to unemployment benefit II, the basic amount for each person and their respective household net income are taken into account to determine the amount of social benefits actually paid.
3.2.4 Housing benefits
Housing benefits for those ineligible for Unemployment Benefit II are paid on request to tenants as well as to owners. The number of persons living in the household, the number of family members, the income and the rent depending on the local rent level determine if a person is entitled to receive housing benefits. In modelling terms, the chargeable household income is calculated by summing up individual incomes, including basic allowances. Then, due to missing information about local rent levels, the lesser of the weighted district average of all rent payments and the maximum state support allowed is taken into account to determine the housing benefits payable.
4. Labour supply module
A key element of FiFoSiM is the analysis of the behavioural responses (labour supply effects) induced by the different tax reform scenarios simulated. Surveys of different kinds of labour supply models, including continuous time models, are provided by Blundell and MaCurdy (1999), Creedy et al. (2002) and Hausman (1985). A discrete choice model has the advantage of offering the possibility of modelling nonlinear budget constraints (e.g. Van Soest, 1995; MaCurdy et al., 1990). Furthermore, a discrete choice between distinct categories of working time seems to us to be more realistic than a continuum of choices because of working time regulations. Following Van Soest (1995), therefore, we apply a discrete choice household labour supply model, assuming that the household’s head and his/her partner jointly maximise a household utility function involving the net income and leisure time of both partners.
More formally, household i (i = 1,...,N) can choose between a finite number (j = 1,...,J) of combinations (yij,lmij,lfij), where yij is the net income, lmij the leisure of the husband and lfij the leisure of the wife of household i in combination j. Based on our data we choose three working time categories for men (unemployed, employed, overtime) and five for women (unemployed, employed, overtime and two part time categories).
Following Christensen et al. (1971) we model the following translog household utility function
where x = (ln yij, ln lmij, ln lfij)' is the vector of the natural logs of the arguments of the utility function. The elements of x enter the utility function in linear (coefficients ß = (ß1, ß2, ß3)’), in quadratic and gross terms (coefficients A(3x3) = (aij)). Using control variables zp (p = 1,...,P), we control for observed heterogeneity in household preferences by defining the parameters ßm and αmn
where m,n = 1,2,3.
In FiFoSiM we use control variables for age, children, region and nationality, which are interacted with the leisure terms in the utility function because variables without variation across alternatives drop out of the estimation in the conditional logit model (Train, 2003).
Following McFadden (1973) and his concept of random utility maximisation (McFadden, 1981; 1985; Greene, 2003) we then add a stochastic error term εij for unobserved factors to the household utility function:
Assuming joint maximisation of the households utility function implies that household i chooses category k if the utility index of category k exceeds the utility index of any other category / ∈ {1,...,J}\{k}, if Uik > Uil. This discrete choice modelling of the labour supply decision uses the probability of i to choose k relative to any other alternative l:
Assuming that εij are independently and identically distributed across all categories j according to a Gumbel (extreme value) distribution, the difference in the utility index between any two categories follows a logistic distribution. This distributional assumption implies that the probability of choosing alternative k ∈ {1,...,J} for household i can be described by a conditional logit model (McFadden, 1973; Greene (2003) and Train (2003) provide textbook presentations):
For the maximum likelihood estimation of the coefficients we assume that the hourly wage is constant across the working hour categories and does not depend on the actual working time. This assumption is common in the literature on structural discrete choice household labour supply models (Van Soest and Das, 2001). For unemployed people we estimate their (possible) hourly wages by using the Heckman correction for sample selection (Heckman, 1976, 1979). A detailed description of these estimations can be found in Fuest et al. (2005b). The household’s net incomes for each working time category are then computed in the tax benefit module of FiFoSiM.
The labour supply module of FiFoSiM is based on GSOEP data, which is enriched by information taken from the FAST data as described in Section 2.3. The sample of tax units is then categorised into six groups according to their assumed labour supply behaviour. We distinguish fully flexible couple households (both spouses are flexible), two types of partially flexible couple households (only the male or the female spouse has a flexible labour supply), flexible female and flexible male single households, and inflexible households. We assume that a person is not flexible in his/her labour supply, meaning he or she has an inelastic labour supply, if a person is
younger than 16 or older than 65 years of age
in education or military service
receiving old-age or disability pensions
self-employed or civil servant.
Every other employed or unemployed person is assumed to have an elastic labour supply. We distinguish between flexible and inflexible persons because the labour supply decision of those assumed to be inflexible (e.g. pensioners, students) is supposed to be based on a different leisure consumption decision (or at least with a different weighting of the relevant determinants) than that of those working full time.
5. CGE module
The tax benefit and labour supply modules of FiFoSiM account only for the household side of the economy. The computable general equilibrium (cGE) module allows us to simulate the overall economic effects of policy changes including the production side. As a result the effects on labour demand, employment and economic growth as well as wage and price levels can be assessed. In this section of the paper, drawing upon Bergs and Peichl (2008), we describe the static CGE module in FiFoSiM, programmed in GAMS/MPSGE (Brooke et al., 1998; Rutherford, 1999), which models a small open economy with 12 sectors and one representative household. For a more general introduction to CGE modelling see Shoven and Whalley (1984,1992) or Kehoe and Kehoe (1994). Although the utility of the CGE module presented here as a stand-alone model is rather limited, in combination with the tax-benefit and labour supply modules, the resulting model, FiFoSiM, becomes a powerful tool. This is illustrated in Section 6, which also outlines some further refinements planned for the CGE module.
5.1 The model
5.1.1 Households
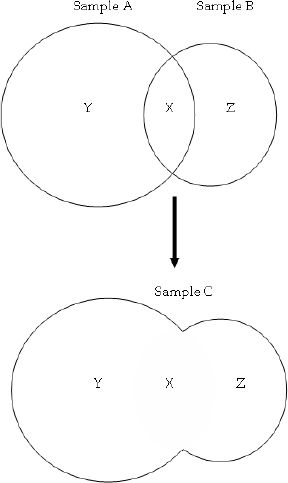
The representative household in the CGE model maximises a nested Constant Elasticity of Substitution (CES) utility function as illustrated in Figure 3.
{kind=link}

Nested CES utility function.
The household first chooses between aggregated consumption (including leisure) today, Q, or in the future, S. The result of this optimisation is the savings supply. The present consumption leisure (or labour leisure) decision then takes place. The household maximises a CES utility function U(C,F) choosing between consumption C and leisure F:
where ß is the value share, ρ the degree of substitutability and σC,F = ρC,F − 1/ρC,F the elasticity of substitution between consumption and leisure.
The budget constraint is:
where pC is the commodity price, w the gross wage, tl the tax rate on labour income, E the time endowment, r the interest rate, tk tax rate on capital income and K the capital endowment. Consumption pCC is financed by labour income w(1−tl)(E−F), capital income r(1−tk)K and the lump sum transfer, T̅LS, that ensures revenue neutrality. Optimising Equation (22) subject to Equation (23) yields the demand functions for goods and leisure. From the latter we calculate the labour supply of the household. As outlined, the CGE module models only one type of labour. It is recognised that this rather strong assumption limits the expressiveness of the household side of the model even more, and is a part of the model for which future refinement is planned (see Section 6).
5.1.2 Firms
A representative firm produces a homogenous output in each production sector according to a nested CES production function. Figure 4 provides an overview of the nesting structure used in FiFoSiM.
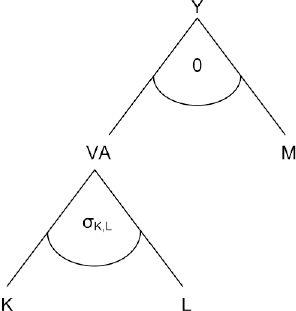{kind=link}
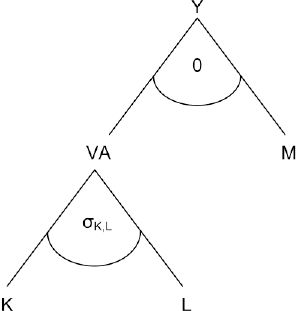
Structure of the nested FiFoSiM production function.
At the top level of the nest, aggregate value added, VA, is combined in fixed proportions, via a Leontief production function, with a material composite, M. M consists of intermediate inputs with fixed coefficients, whereas VA consists of labour, L, and capital, K. The CGE module allows for sector-specific wages and capital costs (although the latter is rarely used) depending on the context of the simulated reform. The optimisation problem at the top level of the nest, in each sector i, can be written as:
In the second level of the nest, the following CES function is used:
where σi = 1/(1−pi) is the constant elasticity of substitution between labour and capital.
The flexible structure of the model allows for different levels of disaggregation ranging from 1 to 3 to 7 to 12 sectors.
5.1.3 Labour market
To account for imperfections in the German labour market, a minimum wage Wimin is introduced as a lower bound for the flexible wages in each sector. The labour supply is therefore rationed:
The minimum wage for each sector is calibrated so that the benchmark represents the current unemployment level in Germany.
5.1.4 Government
The government provides public goods, G, which are financed by input taxes on labour and capital, tl and tk. A lump sum transfer to households completes the budget equation:
5.1.5 Foreign trade
Domestically produced goods are transformed through a constant Elasticity of Transformation function into specific goods for the domestic and the export market, respectively. By the small-open-economy assumption, export and import prices in foreign currency are not affected by the behaviour of the domestic economy. Analogously to the export side, we adopt the Armington assumption (Armington, 1969) of product heterogeneity for the import side. A CES function characterises the choice between imported and domestically produced varieties of the same good. The Armington good enters intermediate and final demand.
5.2 Data and calibration
The model is based on a social accounting matrix (SAM) for Germany which was created using a 2,000 Input-Output-Table (Statistisches Bundesamt, 2005), updated to 2007 using static ageing techniques. See Pyatt and Round (1985) for an introduction to the process of creating a SAM.
The elasticities for the utility and production functions in the CGE model are calibrated based on empirical estimations. The sectoral Armington elasticities are based on Welsch (2001), the elasticity of substitution between labour and capital is assumed to be 0.39, following Chirinko et al. (2004). The elasticity of intertemporal substitution is assumed to be 0.8 (Schmidt and Straubhaar, 1996) as is the elasticity of substitution between consumption and leisure (Auerbach and Kotlikoff, 1987).
5.3 Linking the microsimulation and the CGE module
5.3.1 Review of the literature
Over the last few years, a trend in linking micro and macro models has emerged, as overviewed by Davies (2004). Most of these models deal with trade liberalization in developing countries. FiFoSiM, as far as we know, is the first linked model with a special focus on the modelling and analysis of tax benefit reform proposals. The combination of a micro tax model with a macro CGE model allows the utilisation of the advantages of both types of models.
There are two general possibilities for linking the models. On the one hand, one can completely integrate both models (e.g. Cogneau and Robilliard, 2000; Cororaton et al., 2005). On the other hand, one could combine two separated models via interfaces (e.g. Bourguignon et al., 2003). The first approach requires the complete micro model to be included in the CGE model, requiring high standards of the database and the construction of the integrated model. This often results in various simplifying assumptions.
Following Savard (2003) and Böhringer and Rutherford (2006), the second approach can be differentiated into “top-down”, “bottom-up” or “top-down bottom-up” approaches. The top-down approach computes the macroeconomic variables (price level, growth rates) in a CGE model as inputs for the micro model. The bottom-up approach works the other way around and information from the micro model (elasticities and tax rates) are used in the macro model. Both approaches suffer from the drawback that not all feedback is used. The top-down bottom-up approach combines both methods through recursion. In an iterative process, one model is solved, then information is sent to the other model, which is solved and gives feedback to the first model. This iterative process continues until the two models converge. Böhringer and Rutherford (2006) describe an algorithm for the sequential calibration of a CGE model to use the top-down bottom-up approach with micro models with a large number of households.
5.3.2 Approach in FiFoSiM
FiFoSiM so far uses either the top-down or the bottom-up approach to combine the microsimulation and the CGE module. In the bottom-up linkage, the representative household (income, labour supply, tax payments) in the CGE module is calibrated based on the simulation results of the microsimulation modules. For the top-down linkage, changes of the wage or price level are computed in the CGE model and used in the microsimulation modules for the calculation of net incomes and the labour supply estimation. The top-down bottom-up approach has been executed in FiFoSiM, but so far only manually. Automation of this procedure is one of the planned future improvements to the model (Section 6).
6. Applications and further development
6.1 Applications of FiFoSiM
The development of FiFoSiM started in September 2004. The first operational version of the whole system was ready for use one year later. Since then, the model has been used for analysis whilst undergoing a process of steady improvement.
Specific technical aspects of FiFoSiM have been documented in a series of methodological papers. Peichl (2005) gives an overview of the evaluation of tax reforms using simulation models. Bergs and Peichl (2008) survey the basic principles and possible applications of CGE models. Ochmann and Peichl (2006) give an introduction to the measurement of distributional effects of fiscal reforms.
Alongside these methodological papers, a series of papers have reported upon specific applications of FiFoSiM. Fuest et al. (2005a, 2007a) analyse the fiscal, employment and growth effects of the reform proposal by Mitschke (2004). In Fuest et al. (2006) this analysis is expanded to the negative income tax part (Bürgergeld) of the proposal. Elsewhere Fuest et al. (2007c, 2008a) analyse the efficiency and equity effects of tax simplification. Tax simplification is modelled as the abolition of a set of deductions from the tax base included in the German income tax system. Furthermore, Peichl et al. (2006) analyse the effects of these simplification measures on poverty and affluence in Germany. Finally, Fuest et al. (2007b, 2008b) analyse the distributional effects of different flat tax reform scenarios for Germany, whilst Bergs et al. (2006, 2007) analyse different reform proposals for the taxation of families in Germany. To illustrate the capabilities of FiFoSiM, the following subsection summarises the results from one such application.
6.2 Example: Tax reform proposal by Mitschke
One example of an application of FiFoSiM is our analysis (Fuest et al., 2005a, 2007a) of a reform of the German corporate and personal income taxes proposed by Joachim Mitschke (Mitschke, 2004). In this application, the focus is upon the implications for tax revenue, employment and economic growth, all computed using FiFoSiM. This application demonstrates well the added-value of combining a ‘standard’ static microsimulation model (of consumption) with a cGE model of production.
The Mitschke proposal distinguishes between an introductory phase and a final phase. For both phases the long-term revenue, employment and growth effects are calculated. In the first step, the fiscal effects are analysed in the tax benefit module (Section 3) without taking into account the behavioural reactions of the economic agents. In the second step, we allow for behavioural reactions by estimating the labour supply responses (Section 4). In the third step, the micro data information is used to calibrate the representative household in the cGE module, allowing the computation of the overall employment and growth effects.
To compare the reform proposal with the current tax regime the alternative tax system has to be modelled using the enhanced datasets. For most of the detailed regulations appropriate variables are available in at least one of our datasets.
Nevertheless, some features of the reform require several assumptions and estimations, namely the change to deferred taxation proposed by Mitschke. This concerns, for example, the estimation of the effects of a full taxation of pensions. Only the GSOEP database includes appropriate data because the FAST dataset covers only a fraction of the pensioners who were taxed in 1998. Data on pension payments, therefore, are imputed from GSOEP to FAST*. As a result, the size of this effect can be isolated and estimated in the FAST simulation (€8.4/9.5 billion in the introduction/final phase). It should be noted that the implications for personal income tax revenue pre- and post-reform differ depending on the database used. However, as Table 4 illustrates, the difference between datasets is far smaller than the estimated pre- and post-reform differences in tax-take, discounting any possible behavioural response.
Fiscal effects of reform without behavioural reactions.
| Personal income tax (€ billion) | ||
|---|---|---|
| Reform phase | FAST* | GSOEP* |
| Pre-reform | 181.16 | 180.69 |
| Introduction | 179.15 | 179.08 |
| Final | 168.12 | 166.89 |
Of course, a reform of the size proposed by Mitschke will lead to changes in behaviour. We estimate the labour supply effects by comparing the estimated labour supply in the current system and in the reform alternatives using the model described in Section 4. We find considerable differences in the labour supply reactions between couples and singles as well as between men and women. While married men are anticipated to increase their labour supply most strongly, single women are expected to decrease their labour supply slightly.
The results presented so far are those that might be generated by any standard static microsimulation model. The strength of FiFoSiM is in the linkage to a cGE-model of production-side effects. To estimate the employment and growth effects of Mitschke’s proposed reforms, we linked the tax benefit module to the cGE module, with a minimum wage calibrated to the current unemployment level (11.5%). We then used the microsimulation results to calibrate the representative household in terms of income, labour supply and tax payments. The main results are summarised in Table 5.
Estimated results (FAST*) of the reforms proposed by Mitschke.
| Reform phase | ||
|---|---|---|
| Introduction | Final | |
| PIT revenue | − €2 billion | − €13 billion |
| Labour supply | +103,000 | +251,000 |
| Employment | +370,000 | +540,000 |
| Economic growth | +1.1% | +1.7% |
The shift from the current German tax regime to the taxes proposed by Mitschke would, it is estimated, result in revenue losses amounting to €2 billion in the introductory phase and €13 billion in the final phase. On the other hand, employment would grow by 370,000 full-time jobs, and GDP would increase by 1.1% in the introductory phase. For the final phase, we calculate a total of 540,000 new full-time jobs and a 1.7% increase in GDP. The overall employment effects are larger than the labour supply reactions because reduced costs of labour and capital result in increased labour and investment demand.
6.3 Further development and conclusion
FiFoSiM is a state-of-the-art tax-benefit simulation model for Germany. FiFoSiM consists of three main parts: a static tax-benefit microsimulation model, an econometrically estimated labour supply model and a CGE model. Two specific features distinguish FiFoSiM from other tax benefit models: first, the simultaneous use of two databases for the tax benefit module and second, the linkage of the tax benefit model with a cGE model. As a result, FiFoSiM can be used to analyse a wide variety of potential policy reforms to the complex German tax and transfer system.
Nevertheless, several ideas for the further improvement of FiFoSiM exist. One major aspect of improvement is the modelling of indirect taxes. For this reason, expenditure data is needed and a third data source will have to be included into the FiFoSiM database. It is also intended to improve the micro macro linkage between the microsimulation and the cGE module by automating an iterative top down bottom up approach. Furthermore, the cGE module is to be improved as well, by allowing for a wider variety of household types and more sophisticated modelling of the labour market. Moreover, dynamic modules are planned. A small dynamic version of the cGE module exists, but has not been used for any publication yet. This module will be improved and used in the future. Finally, we expect new releases of the FAST and GSOEP data soon, which will have to be incorporated into the model.
To sum up, the creation of the dual database and the linkage of the tax-benefit model with a cGE model gives users of FiFoSiM a powerful tool for the analysis of various questions regarding the German tax benefit system. Both innovations should be of interest to those seeking to enhance their own microsimulation models.
References
-
1
A theory of demand for products distinguished by place of productionIMF Staff Papers 16:159–176.
- 2
-
3
Projektbericht 1 zur forschungskooperation mikrosimulation mit dem Bundesministerium der Finanzen, Materialien des DIW Berlin, Nr 26Fortschreibungs- und hochrechnungsrahmen für ein einkommen-steuer-simulationsmodell, Projektbericht 1 zur forschungskooperation mikrosimulation mit dem Bundesministerium der Finanzen, Materialien des DIW Berlin, Nr 26, Deutsches Institut für Wirtschaftsforschung, Berlin.
-
4
Numerische Gleichgewichtsmodelle zur Analyse von PolitikreformenZeitschrift für Wirtschaftspolitik 57:1–26.
-
5
Das familienrealsplitting als reformoption in der familienbesteuerungWirtschaftsdienst 86:639–644.
-
6
Reformoptionen der Familienbesteuerung - Aufkommens-, Verteilungs- und Arbeitsangebotseffekte1–27, Jahrbuch fur Wirtschaftswissenschaften, (Review of Economics), 58, 1.
-
7
Labor supply: A review of alternative approachesIn: O Ashenfelter, D Card, editors. Handbook of Labor Economics, 3A. North Holland: Amsterdam. pp. 1559–1695.
-
8
Combining top-down and bottom-up in energy policy analysis: a decomposition approach. ZEW Discussion Paper No 06-007Combining top-down and bottom-up in energy policy analysis: a decomposition approach. ZEW Discussion Paper No 06-007, ftp://ftp.zew.de/pub/zew-docs/dp/dp06007.pdf, accessed 11 November 2008.
-
9
Steuern, transfers und private haushalte. Eine mikroanalytische simulationsstudie der aufkommens- und verteilungswirkungenPeter Lang: Frankfurt am Main.
-
10
Representative versus real households in the macro-economic modelling of inequality. DIAL Document de Travail DT/2003-10Paris: DIAL, Institut de Recherche pour le Developpement.
- 11
-
12
That elusive elasticity: A long-panel approach to estimating the capital-labor substitution elasticity. CESifo-Working Paper No. 1240Munich: CESifo, University of Munich.
-
13
Conjugate duality and the transcendental logarithmic functionEconometrica 39:255–256.
-
14
Growth, distribution and poverty in Madagascar: learning from a microsimulation model in a general equilibrium framework. TMD Discussion Paper 61Washington, DC: International Food Policy Research Institute.
-
15
Statistical matching and microsimulation modelsIn: C F Citro, E A Hanushek, editors. Improving information for social policy decisions: the uses of microsimulation modelling, Vol II Technical Papers. Washington DC: National Academy Press. pp. 62–85.
-
16
Doha scenarios, trade reforms, and poverty in the Philippines: A Computable General Equilibrium analysis. World Bank Policy Research Working Paper 3738Washington, DC: Worldbank.
-
17
Microsimulation Modelling of Taxation and the Labour Market: The Melbourne Institute Tax and Transfer SimulatorCheltenham: Edward Elgar Publishing.
-
18
Microsimulation, CGE and macro modelling for transition and developing economiesMimeo: University of Western Ontario.
-
19
Statistical matching: Theory and practiceStatistical matching: Theory and practice, Wiley, New York.
-
20
FiFo-BerichtAufkommens-, Beschaftigungs- und Wachstumswirkungen einer Steuerreform nach dem Vorschlag von Mitschke, FiFo-Bericht, 05, FiFo Koeln, Universitat zu Köln.
-
21
Dokumentation FiFoSiM: integriertes steuer-transfer-mikrosimulations-und CGE-modell. Finanzwissenschaftliche Diskussionsbeitrage Nr 05 - 03FiFo Koeln: Universitat zu Köln.
-
22
Aufkommens-, beschaftigungs- und wachstumswirkungen einer reform des steuer- und transfersystems nach dem Burgergeld-Vorschlag von Joachim Mitschke. FiFo-Bericht 08–2006FiFo Koeln: Universitat zu Köln.
-
23
Aufkommens-, beschaftigungs- und wachstumswirkungen einer steuerreform nach dem vorschlag von MitschkeBaden-Baden: Nomos.
-
24
Die Flat Tax: Wer gewinnt? Wer verliert? Eine empirische analyse fur DeutschlandSteuer und Wirtschaft 84:22–29.
-
25
Fuhrt Steuervereinfachung zu einer “gerechteren” Einkommensverteilung? Eine empirische Analyse fur DeutschlandPerspektiven der Wirtschaftspolitik 8:20–37.
-
26
Does tax simplification yield more equity and efficiency? An empirical analysis for GermanyCESifo Economic Studies 54:73–97.
-
27
Is flat tax reform feasible in a grown-up democracy of Western Europe? A simulation study for GermanyInternational Tax and Public Finance, forthcoming.
- 28
- 29
-
30
DTC - Desktop Compendium to the German Socio-Economic Panel Study (GSOEP)Berlin: Deutsches Institut für Wirtschaftsforschung.
-
31
Taxes and labor supplyIn: A Auerbach, M Feldstein, editors. Handbook of public economics. Amsterdam: North-Holland. pp. 213–263.
-
32
The common structure of statistical models of truncation, sample selection and limited dependent variables and a simple estimator for such modelsAnnals of Economic and Social Measurement 5:475–492.
- 33
-
34
A primer on static applied general equilibrium modelsFederal Reserve Bank of Minneapolis Quarterly Review 18:2–16.
- 35
-
36
Assessing empirical approaches for analyzing taxes and labor supplyJournal of Human Resources 25:415–490.
-
37
Frontiers in econometrics105–142, Conditional logit analysis of qualitative choice behaviour, Frontiers in econometrics, New York, Academic Press.
-
38
Econometric models of probabilistic choiceIn: C Manski, D McFadden, editors. Structural analysis of discrete data and econometric applications. Cambridge: The MIT Press. pp. 198–272.
-
39
Econometric analysis of qualitative response modelsIn: Z Griliches, M Intrilligator, editors. Handbook of econometrics. Amsterdam: Elsevier. pp. 1396–1456.
-
40
ADJUST FOR WINDOWS - A program package to adjust microdata by the Minimum Information Loss Principle. FFB-Dokumentation No 9Luneburg: Department of Economics and Social Sciences, University of Luneburg.
-
41
De facto anonymised microdata file on income tax statistics 1998. FDZ-Arbeitspapier Nr 5Wiesbaden: Destatis.
-
42
Erneuerung des deutschen einkommensteuerrechts: gesetzestextentwurf undbegrundungKoln: Verlag Otto Schmidt.
-
43
Measuring distributional effects of fiscal reforms. Finanzwissenschaftliche Diskussionsbeitrage Nr 06 - 09FiFo Koeln: Universitat zu Köln.
-
44
Constructing a new data base from existing microdata sets: the 1966 merge fileAnnals of Economic and Social Measurement pp. 325–342.
-
45
Statistical match: evaluation of existing procedures and improvements by using additional informationIn: G H Orcutt, H Quinke, editors. Microanalytic simulation models to support social and financial policy. Amsterdam: Elsevier Science. pp. 401–422.
-
46
Die evaluation von steuerreformen durch simulationsmodelle. Finanzwissenschaftliche Diskussionsbeitrage Nr 05-01FiFo Koeln: Universitat zu Köln.
-
47
Documentation FiFoSiM: integrated tax benefit microsimulation and CGE model. Finanzwissenschaftliche Diskussionsbeitrage Nr 06 - 10FiFo Koeln: Universitat zu Köln.
-
48
Measuring richness and poverty - a micro data application to Germany and the EU-15. CPE discussion paper No 06-11FiFo Koeln: Universitat zu Köln.
- 49
-
50
Erneuerung der stichprobe des ESt-,odells des Bundesministeriums der Finanzen auf basis der lohn- und einkommensteuerstatistik 1995. Technical Report, GMD - Forschungszentrum Informationstechnik GmbHErneuerung der stichprobe des ESt-,odells des Bundesministeriums der Finanzen auf basis der lohn- und einkommensteuerstatistik 1995. Technical Report, GMD - Forschungszentrum Informationstechnik GmbH, St. Augustin.
-
51
Report on exact and statistical matching techniques. Statistical Policy Working Paper 5, Federal Committee on Statistical MethodologyWashington, DC: Office of Federal Statistical Policy and Standards.
- 52
-
53
The central role of the propensity score in observational studies for causal effectsBiometrika 70:41–55.
- 54
-
55
Applied General Equilibrium modeling with MPSGE as a GAMS subsystem: an overview of the modeling framework and syntaxComputational Economics 14:1–46.
-
56
Poverty and income distribution in a CGE-Household micro-simulation model: Top-down/bottom up approach. Working Paper 03-43, CIRPEE Centre interuniversitaire sur le risqueMontreal: les politiques economiques et l’emploi.
- 57
-
58
Bevolkerungsentwicklung und wirtschaft-swachstum - eine simulationsanalyse fur die SchweizSchweizerische Zeitschrift fur Volkswirtschaft und Statistik 132:395–414.
-
59
Applied general equilibrium models of taxation and international trade: An introduction and surveyJournal of Economic Literature 22:1007–1051.
- 60
- 61
- 62
- 63
-
64
The German Socio-Economic Panel (GSOEP) after more than 15 years - overviewVierteljahrshefte zur Wirtschaftsforschung 70:7–14.
-
65
Volkswirt-schaftliche gesamtrechnungen: input-output-rechnung. Fachserie 18, Reihe 2Wiesbaden: Destatis.
-
66
Combining household income and expenditure data in policy simulationsReview of Income and Wealth 48:517–536.
- 67
-
68
Structural models of family labor supply: a discrete choice approachJournal of Human Resources 30:63–88.
-
69
Family labor supply and proposed tax reforms in the NetherlandsDe Economist 149:191–218.
-
70
Tax-benefit microsimulation models for Germany: a surveyIAW-Report / Institut fuer Angewandte Wirtschaftsforschung (Tubingen) 32:55–74.
-
71
Armington elasticities and product diversity in the European Community: a comparative assessment of four countries. Working PaperUniversity of Oldenburg.
Article and author information
Author details
Acknowledgements
The authors would like to thank Christian Bergs, Erika Berthold, Frank Brenneisen, Stephan Dobroschke, Marios Doulis, Clemens Fuest, Sven Heilmann, Paul Williamson and two anonymous referees for their helpful contributions. The usual disclaimer applies.
Publication history
- Version of Record published: June 30, 2009 (version 1)
Copyright
© 2009, Peichl and Schaefer
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.